

 Il y a peu, Google a mis à disposition des développeurs TensorFlow, sa solution dapprentissage profond, une technique dapprentissage automatique qui exploite principalement des réseaux neuronaux de très grande taille : lidée est de laisser lordinateur trouver lui-même, dans sa phase dapprentissage, des abstractions de haut niveau par rapport aux données disponibles. Par exemple, pour reconnaître des chiffres dans des images, ces techniques détermineront une manière danalyser limage, den récupérer les éléments intéressants, en plus de la manière de traiter ces caractéristiques et den inférer le chiffre qui correspond à limage.
Il y a peu, Google a mis à disposition des développeurs TensorFlow, sa solution dapprentissage profond, une technique dapprentissage automatique qui exploite principalement des réseaux neuronaux de très grande taille : lidée est de laisser lordinateur trouver lui-même, dans sa phase dapprentissage, des abstractions de haut niveau par rapport aux données disponibles. Par exemple, pour reconnaître des chiffres dans des images, ces techniques détermineront une manière danalyser limage, den récupérer les éléments intéressants, en plus de la manière de traiter ces caractéristiques et den inférer le chiffre qui correspond à limage.Microsoft vient tout juste dannoncer sa solution concurrente, nommée CNTK (computational network toolkit), elle aussi disponible gratuitement sous une licence libre de type MIT sur GitHub. Cette annonce poursuit la série douvertures de code annoncées par Microsoft dernièrement, comme ChakraCore, son moteur JavaScript.
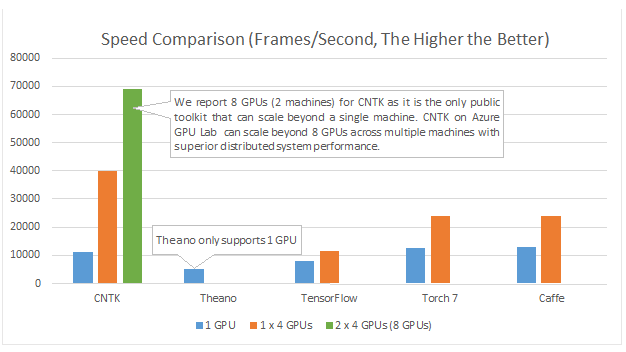
Ces développements ont eu lieu dans le cadre de la recherche sur la reconnaissance vocale : les équipes de Microsoft estimaient que les solutions actuelles avaient tendance à les ralentir dans leurs avancées. Quelques chercheurs se sont lancés dans laventure décrire eux-mêmes un code de réseaux neuronaux très efficace, accéléré par GPU et leurs efforts ont porté leurs fruits, puisque, selon leurs tests, CNTK est plus efficace que Theano, TensorFlow, Torch7 ou Caffe, les solutions les plus avancées dans le domaine du logiciel libre.
Microsoft nest pas la seule société à beaucoup parier sur les GPU : NVIDIA également croit fort aux GPU pour accélérer lapprentissage profond. Pour la sortie de la dernière version de CUDA, la solution de NVIDIA pour le calcul sur GPU, leur bibliothèque cuDNN proposait un gain dun facteur deux pour lapprentissage dun réseau.
Lavantage des GPU dans le domaine est multiple. Tout dabord, leur architecture sadapte bien au type de calculs à effectuer. Ensuite, ils proposent une grande puissance de calcul pour un prix raisonnable : pour obtenir la même rapidité avec des processeurs traditionnels (CPU), il faudrait débourser des milliers deuros, par rapport à une carte graphique à plusieurs centaines deuros à ajouter dans une machine existante. Ainsi, les moyens à investir pour commencer à utiliser les techniques dapprentissage profond sont relativement limités. Cependant, la mise à léchelle est plus difficile : lapprentissage sur plusieurs GPU en parallèle est relativement difficile, toutes les bibliothèques ne le permettent pas. Pour réaliser de véritables progrès algorithmiques, il faut sortir le carnet de chèques, avec des grappes de machines, nettement moins abordables.
Source : Microsoft releases CNTK, its open source deep learning toolkit, on GitHub.
Et vous ?
 Qu'en pensez-vous ?
Qu'en pensez-vous ?Ce contenu a été publié dans HPC et calcul scientifique, Matériel par dourouc05.
Vous avez lu gratuitement 19 468 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.


