

 Dans le développement de jeux vidéo, la création de modèles 3D prend une bonne partie du temps total, mais aussi des gens compétents. Certains ont donc eu lidée dautomatiser cette partie, par exemple à laide de réseaux neuronaux, la tarte à la crème actuelle. Lidée très générale est simple : on entre une image, on ressort un modèle 3D. Un peu plus en détail, on voit déjà apparaître des zones dombre : on peut traiter assez facilement des images avec des réseaux neuronaux, mais quid des modèles 3D ? Quelle architecture pourrait-on utiliser pour relier les deux ? Comment effectuer lentraînement du système ? Commençons par la troisième partie.
Dans le développement de jeux vidéo, la création de modèles 3D prend une bonne partie du temps total, mais aussi des gens compétents. Certains ont donc eu lidée dautomatiser cette partie, par exemple à laide de réseaux neuronaux, la tarte à la crème actuelle. Lidée très générale est simple : on entre une image, on ressort un modèle 3D. Un peu plus en détail, on voit déjà apparaître des zones dombre : on peut traiter assez facilement des images avec des réseaux neuronaux, mais quid des modèles 3D ? Quelle architecture pourrait-on utiliser pour relier les deux ? Comment effectuer lentraînement du système ? Commençons par la troisième partie. Quand il sagit de transformations du genre, il est courant dutiliser des GAN, des réseaux antagonistes génératifs : dans ce cas-ci, par exemple, un réseau neuronal crée un modèle 3D à partir dune image 2D, un autre réseau décide si le modèle 3D correspond bien à limage 2D. Ainsi, on dispose dun mécanisme qui peut améliorer le générateur de modèles 3D. Cependant, comment décider si le modèle 3D correspond à limage ? Pour ce faire, il faut utiliser un moteur de rendu, auquel on fournit le modèle 3D produit : il ressort une image, que lon compare avec limage dentrée.
Et si on simplifiait la chose, en intégrant le moteur de rendu dans le réseau neuronal (au moins pendant son entraînement) ? Ainsi, on a un réseau qui prend une image en entrée, ressort un modèle 3D, qui passe dans un moteur de rendu, on calcule lerreur du modèle en comparant limage obtenue à la sortie du moteur de rendu avec limage dentrée. Il faut juste arriver à dériver le moteur de rendu, ce que lon arrive à faire depuis quelques années, de manière approchée (mais de manière exacte avec du lancer de rayons). Les chercheurs introduisent cependant une nouvelle approche, DIB-R (differentiable interpolation-based renderer), avec un mélange dinterpolation locale (comme le fait tout moteur de rendu, par exemple à léchelle dun triangle éclairé) et dagrégation globale.

Ensuite, quelle architecture de réseau faut-il utiliser ? Le choix des chercheurs de NVIDIA sest porté sur un encodeur-décodeur, pour (en principe) réduire limage à quelques paramètres très significatifs (par exemple : oiseau, petit, jaune). Lencodeur peut donc notamment effectuer une tâche de reconnaissance dobjet.
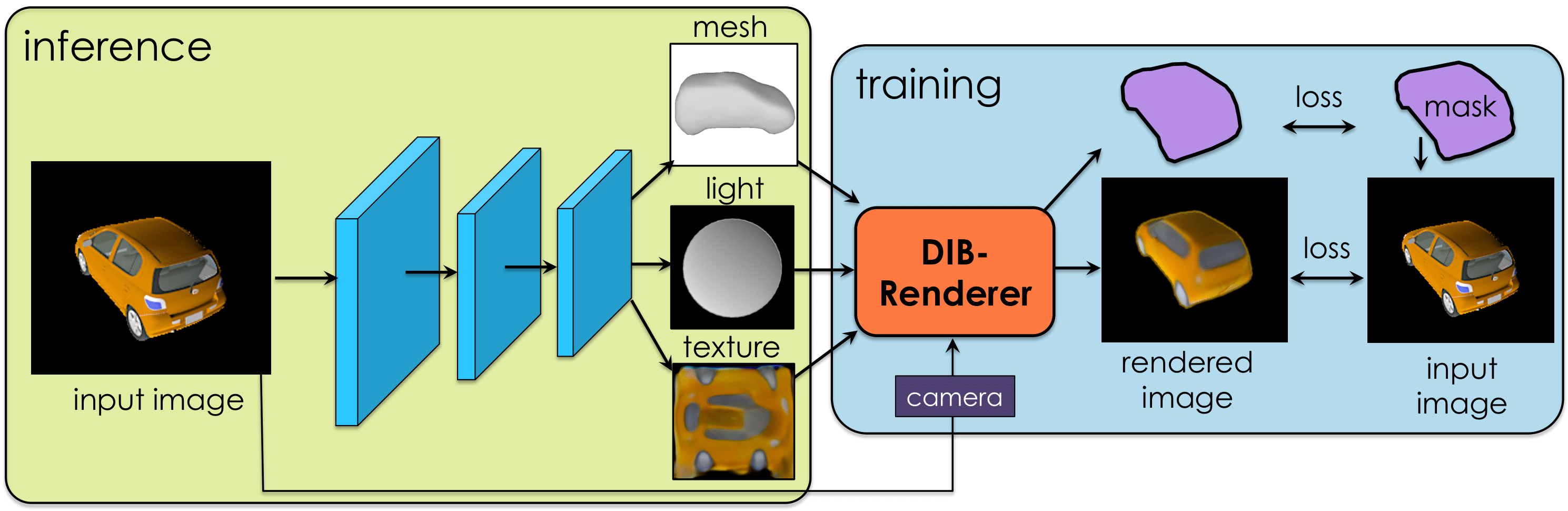
Comment représenter un modèle 3D ? Les chercheurs ont pris la manière la plus classique de faire : ils présupposent que le modèle peut être formé à partir dune sphère avec une discrétisation donnée ; la sortie du modèle est la position et la couleur de chaque arête de cette sphère. Dune certaine manière, cette sortie est une image à six dimensions (trois pour la position, trois pour la couleur), doù lutilisation dune architecture avec des convolutions pour gérer la sortie. (Pour obtenir de meilleurs résultats, les chercheurs ont aussi étendu leur travail pour générer une texture en sortie, ainsi que des informations déclairage.) Larrière-plan de limage est extrait et affiché derrière le modèle 3D.

Le résultat est une application qui peut générer des modèles 3D en moins de cent millisecondes. Ces derniers ne sont pas encore parfaits (bien que meilleurs que les approches précédentes), mais sont une bonne base pour un artiste : il peut gagner beaucoup de temps en partant de ces modèles plutôt que de zéro. Son entraînement a néanmoins pris deux jours.
Source : larticle et son supplément.
Voir aussi : le code source de DIB-R.
Vous avez lu gratuitement 6 916 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.


