

 Lapprentissage automatique est une discipline issue des statistiques qui cherche à effectuer des prédictions. Par exemple, dans un problème de classification : sachant la valeur dune série de variables, eu égard aux données disponibles, quelle classe attribuer à léchantillon que lon vient de recevoir ? Pour ce faire, lalgorithme dapprentissage extrait des corrélations dans les données quil reçoit. Lune des techniques pour y arriver est dentraîner un réseau de neurones, une idée très vaguement inspirée par la biologie et lorganisation des cerveaux.
Lapprentissage automatique est une discipline issue des statistiques qui cherche à effectuer des prédictions. Par exemple, dans un problème de classification : sachant la valeur dune série de variables, eu égard aux données disponibles, quelle classe attribuer à léchantillon que lon vient de recevoir ? Pour ce faire, lalgorithme dapprentissage extrait des corrélations dans les données quil reçoit. Lune des techniques pour y arriver est dentraîner un réseau de neurones, une idée très vaguement inspirée par la biologie et lorganisation des cerveaux.Cependant, lapprentissage risque de patiner dans le cas où le nombre de classes possibles est grand. Par exemple, la classification de spam ne fait appel quà deux classes : spam ou pas (ham). Au contraire, prédire un produit quun consommateur pourrait acheter nécessite de retourner un produit dans le catalogue dun magasin (de par le monde, Amazon vendrait pas loin de trois milliards de produits différents ). Si on prend un réseau neuronal assez basique, on se retrouve avec au moins deux mille paramètres à apprendre pour chaque produit : dans le cas dun magasin en ligne de grande taille (cent millions de produits à létalage), cela fait deux cent milliards de valeurs numériques à déterminer, presque un téraoctet et demi sans compter les données sur lesquelles entraîner ce modèle. Cest beaucoup trop ! Surtout que lentraînement est surtout effectué sur des cartes graphiques, qui ont du mal à dépasser les trente-deux gigaoctets de mémoire pour le moment
Des chercheurs de luniversité Rice, aux États-Unis, ont eu lidée dappliquer une série de transformations aléatoires sur les données pour que cet entraînement soit plus facilement réalisable. Ils ont décidé dappeler leur algorithme MACH (merged average classifiers via hashing). Aléatoirement, les cent millions de classes sont divisées en un certain nombre de seaux (peu nombreux : par exemple, dix ou cinquante), on entraîne alors le réseau neuronal (ou nimporte quel autre algorithme dapprentissage) à prédire dans quel seau doit aller chaque échantillon (on parle donc de métaclasse).
Formellement, il ne sagit pas dune répartition aléatoire, mais selon une fonction de hachage (idéalement, une fonction de hachage a une sortie qui ressemble furieusement à un nombre aléatoire). Ce modèle nest pas encore utile : il faut répéter ce processus un grand nombre de fois, toujours en créant les métaclasses plus ou moins au hasard. Ensuite, quand on dispose dun nombre suffisant de modèles, on peut leur demander leur prédiction : la valeur que cet empilement de modèles doit produire est lélément qui est présent dans toutes les prédictions. (Plus précisément, les chercheurs travaillent avec des probabilités que léchantillon appartienne à une métaclasse, ce qui permet de gérer le cas où les différents modèles ne prédisent pas des métaclasses qui se superposent : cest le théorème 1 de leur article.)
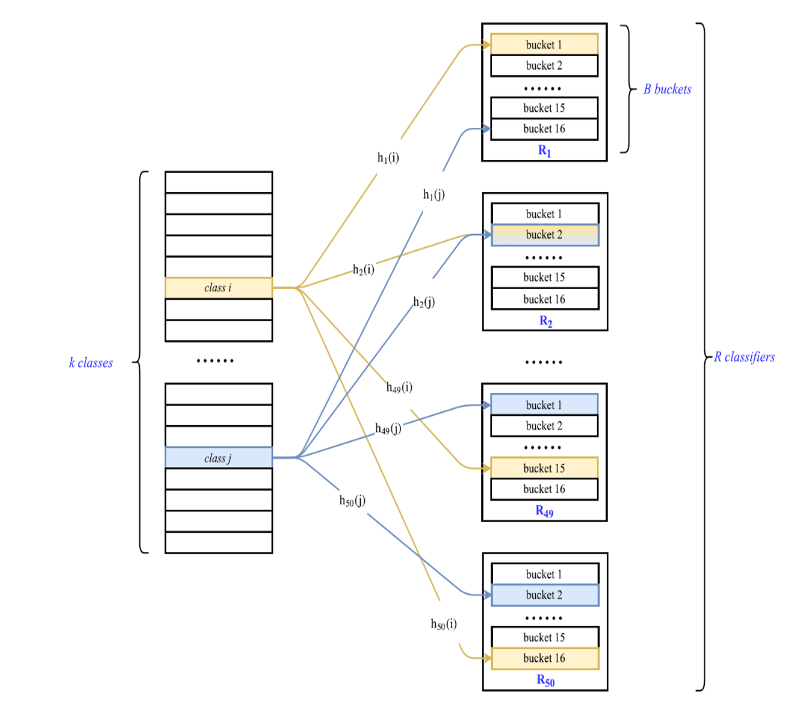
Tout lintérêt de cette approche se situe dans la création arbitraire de métaclasses : les classificateurs à entraîner sont beaucoup plus petits, ce qui règle le problème de la taille du modèle complet. Cependant, il existait déjà des techniques pour gérer des nombres extrêmement importants de classes, comme Parabel, FastXML ou la création de plongements denses (représenter une classe avec quelques variables). Néanmoins, elles souffrent de problèmes de performance : leur découpage nest jamais assez indépendant (lentraînement des modèles ne peut pas se faire en parallèle sur des machines ne communiquant pas) ; de plus, MACH effectue de meilleures prédictions (du moins en regardant le rappel et en maintenant la précision à 100 %).
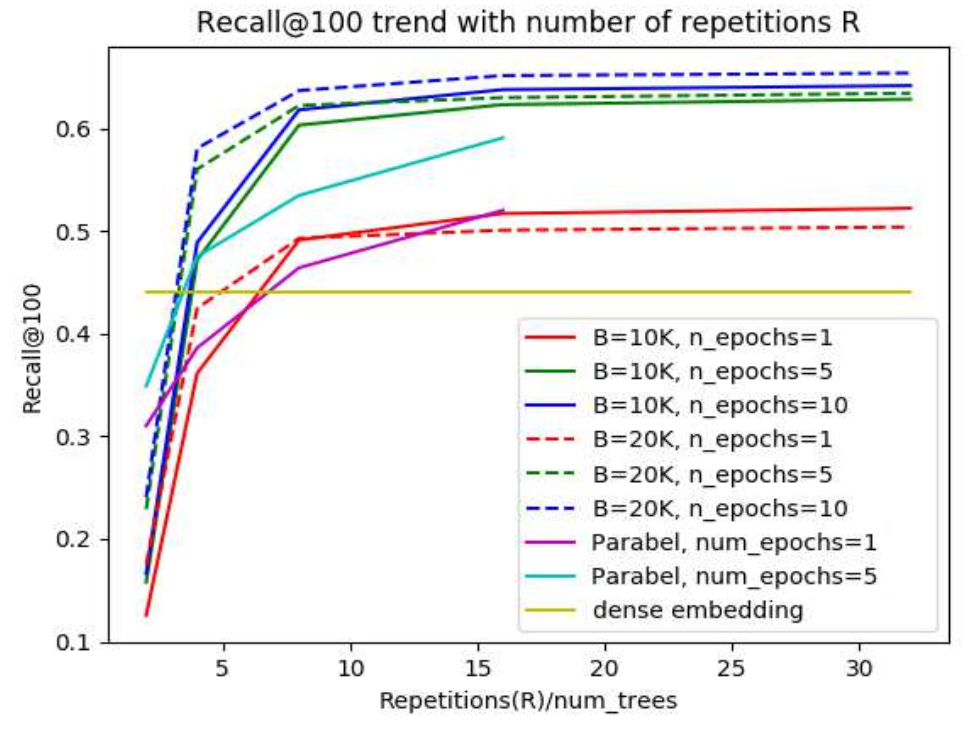
Source : article publié à NeurIPS 2019.
Vous avez lu gratuitement 14 584 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.