

 Lapprentissage automatique a beaucoup profité des cartes graphiques pour diminuer les temps de traitement. En réalité, non, pas tellement lapprentissage automatique : surtout une technique en particulier, lapprentissage profond, à laide de réseaux neuronaux de très grande taille. Cependant, il existe bon nombre dalgorithmes dapprentissage qui pourraient simplémenter sur une carte graphique. De plus, les traitements sur les données peuvent aussi profiter de cette manne de puissance de calcul : calculer une moyenne, par exemple, peut se faire extrêmement efficacement sur une carte graphique (au point que le temps de transfert des données est largement plus grand que celui de calcul).
Lapprentissage automatique a beaucoup profité des cartes graphiques pour diminuer les temps de traitement. En réalité, non, pas tellement lapprentissage automatique : surtout une technique en particulier, lapprentissage profond, à laide de réseaux neuronaux de très grande taille. Cependant, il existe bon nombre dalgorithmes dapprentissage qui pourraient simplémenter sur une carte graphique. De plus, les traitements sur les données peuvent aussi profiter de cette manne de puissance de calcul : calculer une moyenne, par exemple, peut se faire extrêmement efficacement sur une carte graphique (au point que le temps de transfert des données est largement plus grand que celui de calcul).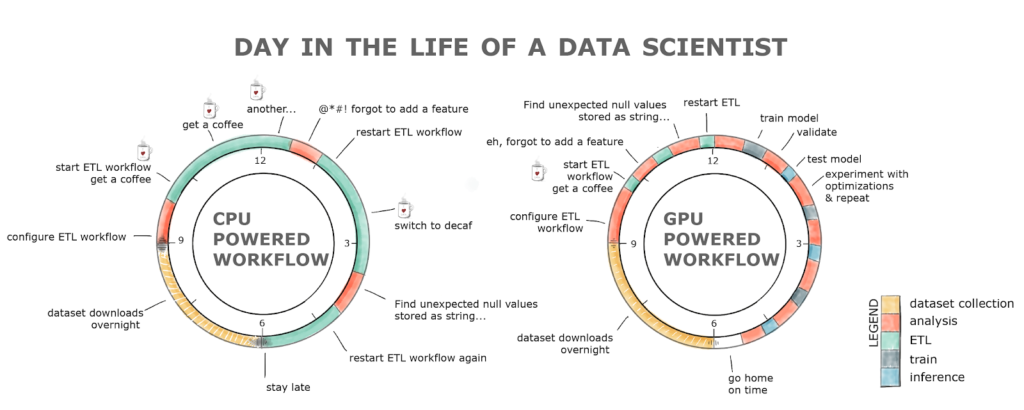
Cest en remarquant cet état de fait et labsence de solution libre et ouverte pour lapprentissage automatique au sens large que NVIDIA a décidé de travailler avec la communauté (ce qui nest pas si fréquent !) pour apporter le calcul sur cartes graphiques à des bibliothèques très présentes dans lenvironnement des sciences des données : Apache Arrow (une base de données orientée colonne stockée en mémoire), Pandas (une bibliothèque Python pour la manipulation de jeux de données à laide dobjets data frame, des matrices dont les colonnes portent des noms) et scikit-learn (la bibliothèque Python de référence pour lapprentissage automatique).
Cette solution sappelle RAPIDS et est déjà disponible (les sources aussi). Elle sappuie sur Apache Arrow et Pandas pour linterface : RAPIDS propose notamment une implémentation des data frames sur processeur graphique, nommée cuDF (une bibliothèque toujours en développement : limplémentation de bas niveau en C et sa couche de liaison Python sont en cours de fusion). La deuxième partie concerne lapprentissage proprement dit. Là, NVIDIA propose cuML (qui contient le module Python cuSKL, pour faire référence à scikit-learn) pour travailler sur les data frames hébergés sur un processeur graphique. La distribution de RAPIDS inclut aussi XGBoost, un algorithme de dopage très populaire à base darbres de décision.
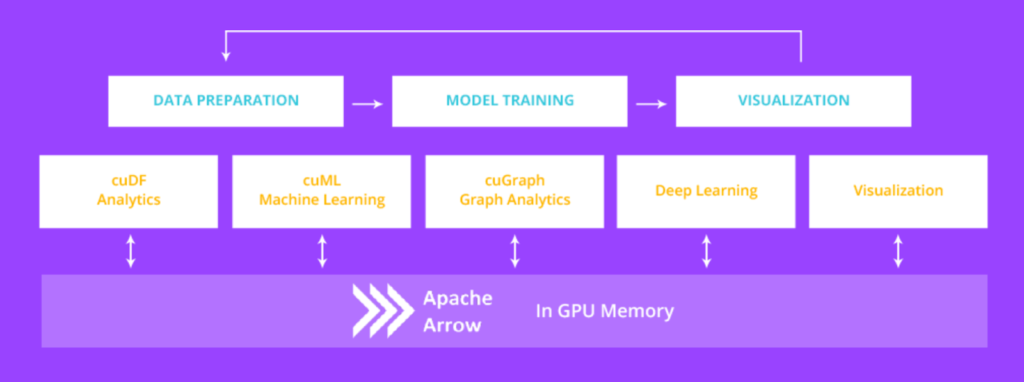
RAPIDS peut dores et déjà sinstaller, notamment via Docker. Bien évidemment, on peut voir derrière ce mouvement la volonté de NVIDIA de sassurer que son API propriétaire CUDA est bien présente dans tous les domaines de croissance, au lieu dOpenCL (qui permettrait dutiliser le code tel quel sur des processeurs graphiques AMD, par exemple).
Sources : RAPIDS Accelerates Data Science End-to-End, Getting Answers Faster: NVIDIA and Open-Source Ecosystem Come Together to Accelerate Data Science.
Vous avez lu gratuitement 6 803 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

