

 Intel livre ses premiers Xeon Phi Knights Landing
Intel livre ses premiers Xeon Phi Knights LandingLa nouvelle mouture de ses coprocesseurs concurrence NVIDIA en apprentissage profond
Il y a de cela un an, la nouvelle mouture des processeurs Intel Xeon Phi, nom de code Knights Landing, était annoncée : ces processeurs sont maintenant livrés aux fournisseurs de matériel HPC. Avec ces nouvelles puces, Intel vise le même segment que NVIDIA avec ses cartes graphiques (GPU) de génération Pascal : lapprentissage profond, le calcul scientifique de haute performance (HPC).
Actuellement, quatre modèles sont disponibles, avec un nombre de curs variable (de soixante-quatre à septante-deux) et des fréquences aussi variables (entre 1,3 et 1,5 GHz), des caractéristiques proches des GPU actuels comme NVIDIA Pascal. Tous sont livrés avec seize gigaoctets de mémoire vive (MCDRAM), empilée et très proche du processeur, pour une bande passante de presque cinq cents gigaoctets par seconde. Ces différentes puces représentent des compromis différents : la plus puissante (7290, 3,46 Tflops) est la plus chère (6294 $), avec un produit bien plus abordable au niveau du téraflops par euro (7210 à 2438 $ pour 2,66 Tflops) ; lune optimise le ratio performance par watt (7250, 3,05 Tflops pour 215 W, là où le 7290 fournit 3,46 Tflops pour 245 W) et la dernière la mémoire disponible par cur (7230, soixante-quatre curs, comme le 7210, mais la mémoire a une fréquence plus élevée).

Au niveau des chiffres bruts, ces processeurs ne dépassent pas loffre de NVIDIA : « à peine » trois téraflops et demi pour le plus haut de gamme, quand les GPU NVIDIA Pascal atteignent cinq téraflops (et une bande passante de cinquante pour cent plus élevée, à sept cent vingt gigaoctets par seconde). Par contre, selon les applications, à cause de la différence darchitecture fondamentale, les résultats varient énormément (les Xeon Phi sont organisés comme des processeurs traditionnels : chaque cur peut exécuter une instruction propre, contrairement aux GPU, où la même instruction est exécutée sur un grand nombre de curs). Ainsi, pour de la simulation de dynamique moléculaire, pour le test de performance LAMPPS, un Xeon Phi de milieu de gamme (7250) a fonctionné cinq fois plus vite en consommant huit fois moins de mémoire quun GPU NVIDIA K80 (la génération précédant les Pascal). Pour de la visualisation par lancer de rayon, Intel indique être cinq fois plus rapide ; le facteur descend à trois pour de la simulation de risque financier. Ces comparaisons ne sont pas entièrement équitables, à cause de la différence dâge entre les processeurs, mais indiquent la tendance quIntel veut montrer. Ces résultats devront être confirmés par des indépendants pour être fiables.
Parmi les tests de performance, Intel sest aussi orienté vers lapprentissage profond, branche dans laquelle NVIDIA simpose actuellement. Ce domaine est actuellement à la pointe de la recherche, avec des résultats de plus en plus intéressants : cest grâce à des techniques de ce genre que Google a pu battre le joueur le plus fort au monde au jeu de go. Sur un même jeu de test, un Xeon Phi 7250 a obtenu sa réponse en cinquante fois moins de temps quun seul processeur traditionnel ; avec quatre tels Xeon Phi, les temps de calcul ont été réduits dun facteur deux par rapport à quatre GPU NVIDIA K80.
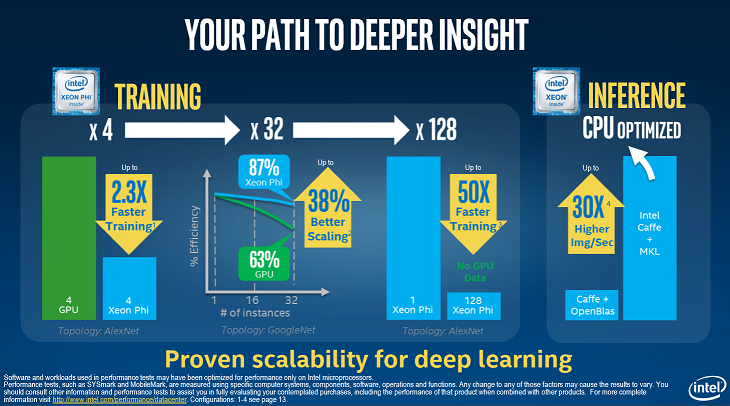
Intel précise également quil est plus facile de programmer ses processeurs Xeon Phi : ils embarquent beaucoup plus de curs, mais cest la seule différence avec les processeurs habituels de nos PC, alors quil faut réécrire complètement son code (ou utiliser des API adaptées) pour les GPU, avec une phase doptimisation du code qui nécessite des compétences plus spécifiques. La nouvelle génération de Xeon Phi apporte cependant une distinction plus importante : ces processeurs Intel pourront être utilisés comme processeurs principaux (pas seulement comme cartes dextension), ce qui évite les opérations de transfert de données, très limitantes pour la performance des applications actuelles. Il reste cependant à déterminer si ces processeurs seront suffisamment rapides pour effectuer toutes les opérations des applications qui leur sont soumises (ils fonctionnent à une fréquence réduite par rapport aux processeurs habituels : ils excellent dans le traitement parallèle, mais pas en série, qui constitue parfois une part importante du code à exécuter).
Ni ces nouveaux Xeon Phi ni les GPU NVIDIA Pascal ne sont actuellement utilisés à grande échelle pour du calcul scientifique. Cependant, ces premiers résultats montrent que les deux jouent dans la même cour. Si les mesures dIntel se généralisent, ils deviendront un concurrent plus que très sérieux de NVIDIA, notamment dans le marché en expansion de lapprentissage profond ; sils ont en plus lavantage du prix, la dominance de NVIDIA sera vite mise à mal.
Sources : Intel Takes on NVIDIA with Knights Landing Launch, Intels Knights Landing: Fresh x86 Xeon Phi lineup for HPC and AI, Intel Xeon Phi Knights Landing Now Shipping; Omni Path Update, Too.
Vous avez lu gratuitement 1 608 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

